Split-Ensemble: Efficient OOD-aware Ensemble via Task and Model Splitting
Abstract
Uncertainty estimation is crucial for machine learning models to detect out-of-distribution (OOD) inputs. However, the conventional discriminative deep learning classifiers produce uncalibrated closed-set predictions for OOD data. A more robust classifiers with the uncertainty estimation typically require a potentially unavailable OOD dataset for outlier exposure training, or a considerable amount of additional memory and compute to build ensemble models. In this work, we improve on uncertainty estimation without extra OOD data or additional inference costs using an alternative Split-Ensemble method. Specifically, we propose a novel subtask-splitting ensemble training objective, where a common multiclass classification task is split into several complementary subtasks. Then, each subtask's training data can be considered as OOD to the other subtasks. Diverse submodels can therefore be trained on each subtask with OOD-aware objectives. The subtask-splitting objective enables us to share low-level features across submodels to avoid parameter and computational overheads. In particular, we build a tree-like Split-Ensemble architecture by performing iterative splitting and pruning from a shared backbone model, where each branch serves as a submodel corresponding to a subtask. This leads to improved accuracy and uncertainty estimation across submodels under a fixed ensemble computation budget. Empirical study with ResNet-18 backbone shows Split-Ensemble, without additional computation cost, improves accuracy over a single model by 0.8%, 1.8%, and 25.5% on CIFAR-10, CIFAR-100, and Tiny-ImageNet, respectively. OOD detection for the same backbone and in-distribution datasets surpasses a single model baseline by, correspondingly, 2.2%, 8.1%, and 29.6% mean AUROC.
Video
Coming soon
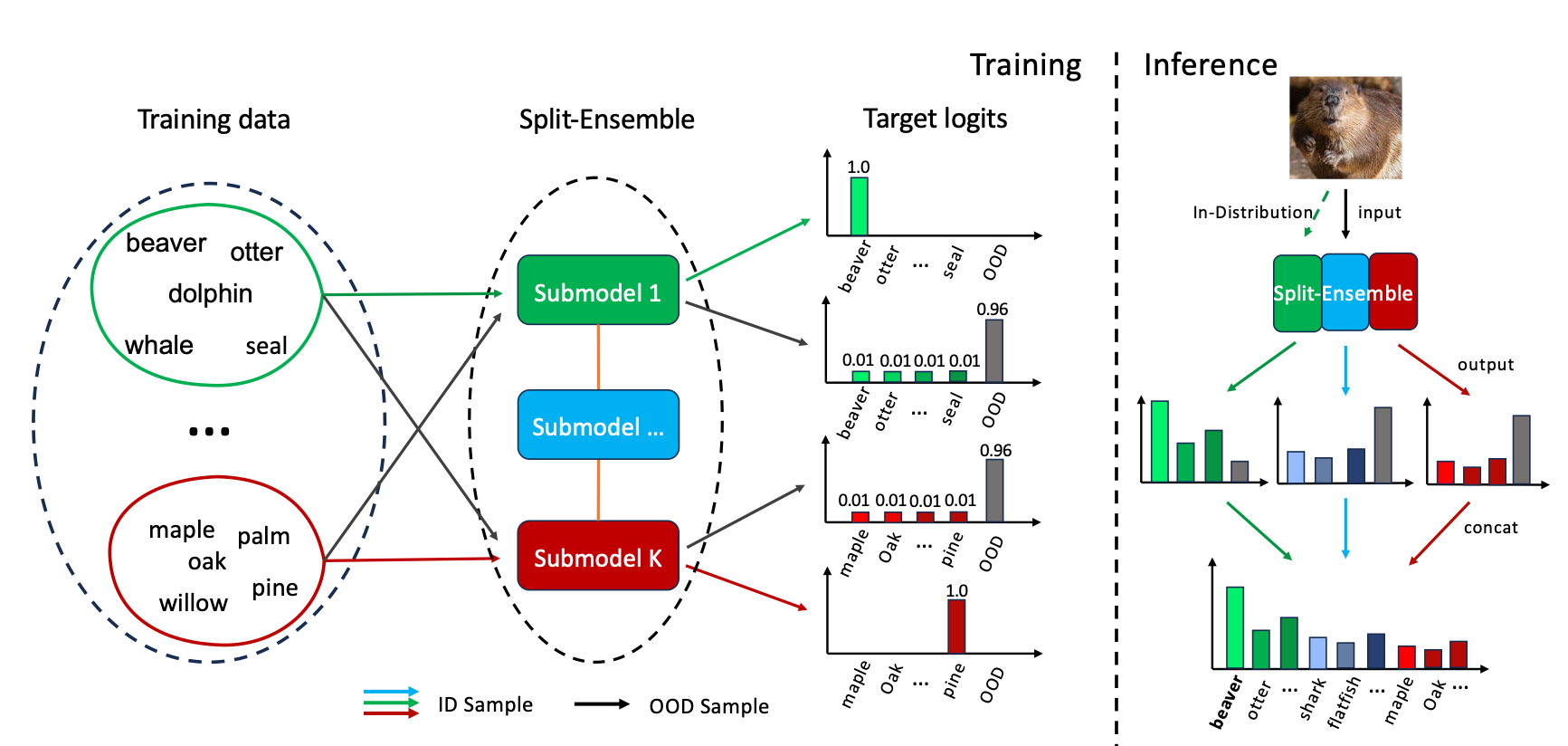
Sub-task Splitting
Each submodel learns its subtask using a subset of the original training data. OOD detection by outlier exposure training is realized using other subtasks' examples. Concatenated ID logits from all submodels implement the original multiclass classification task.
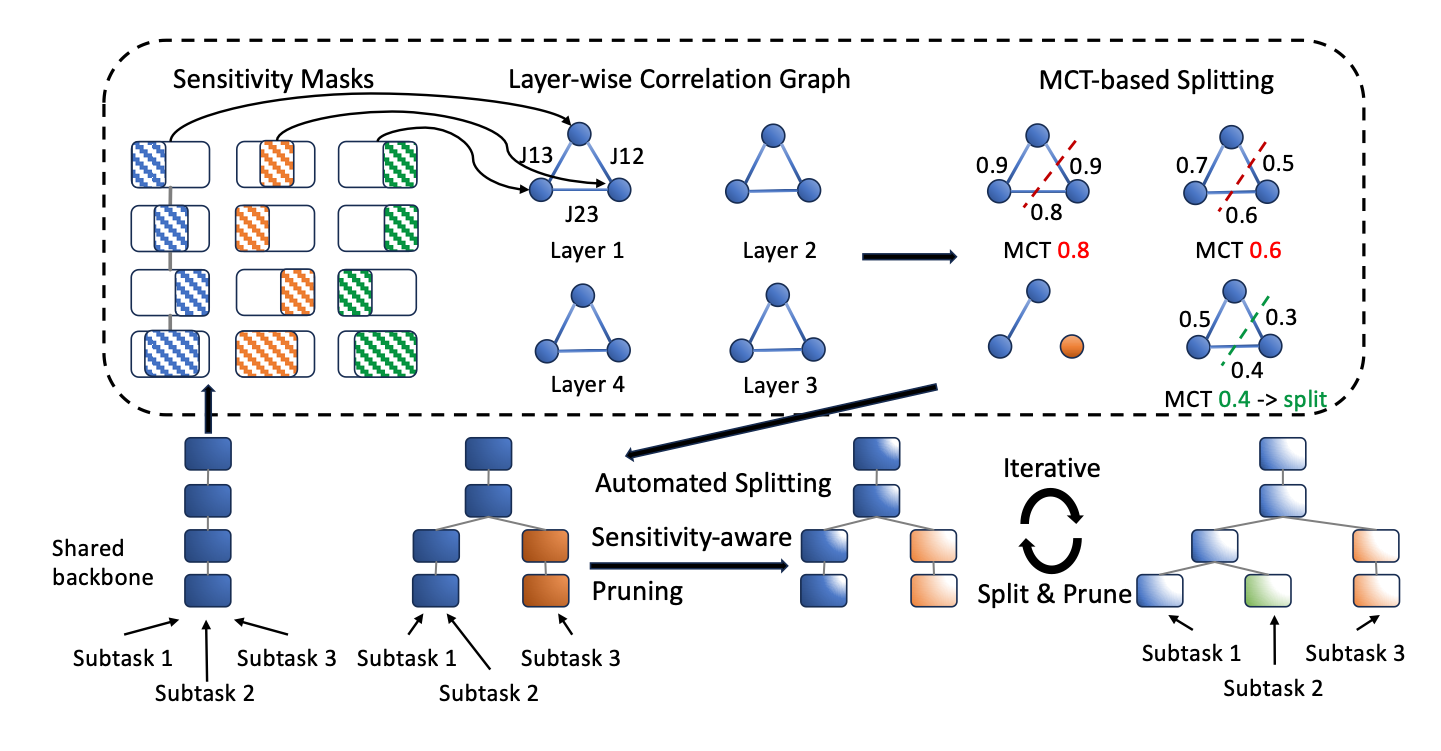
Iterative Splitting & Pruning
Starting from a shared backbone, we compute the layer-wise sensitivity mask $\mathcal{M}$ for each subtask loss, and calculate pair-wise IoU score $J$ across different subtasks for the layer-wise correlation graph. Model is split at the layer with a small minimal cutting threshold (MCT), and, then, is pruned globally. Applying splitting and pruning in an iterative fashion leads to the final Split-Ensemble architecture that satisfies the cost constraints.
Visualization on Learned Features
We visualize the learned feature map activations of a Split-Ensemble model across different layers using Score-CAM. The shared feature maps, delineated by dashed lines, represent the common features extracted across different submodels, emphasizing the model's capacity to identify and leverage shared representations. The distinct feature maps outside the dashed boundaries correspond to specialized features pertinent to individual sub-tasks, demonstrating the Split-Ensemble model's ability to focus on unique aspects of the data when necessary. This visualization underscores the effectiveness of the Split-Ensemble architecture, highlighting its dual strength in capturing both shared and task-specific features within a single, cohesive framework, thereby bolstering its robustness and adaptability in handling diverse image classification and OOD detection tasks.

BibTeX
Coming Soon
Acknowledgements
Thanks Nerfies for their wonderful website.