PiMAE: Point cloud and Image Interactive Masked Autoencoders for 3D Object Detecion
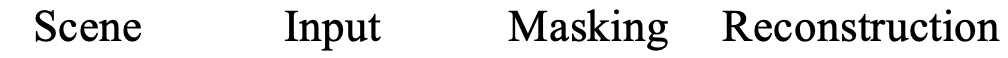
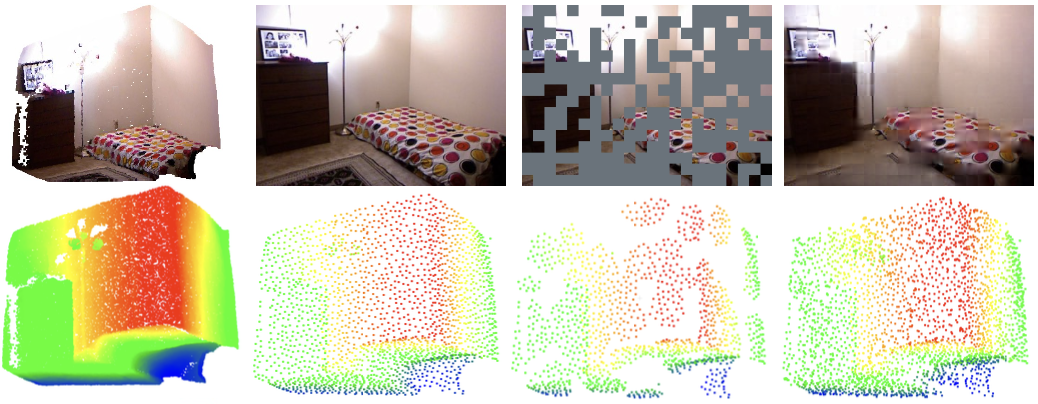





PiMAE reconstructs masked 3D point cloud & RGB images simultaneously.
Abstract
Masked Autoencoders learn strong visual representations and achieve state-of-the-art results in several independent modalities, yet very few works have addressed their capabilities in multi-modality settings. In this work, we focus on point cloud and RGB image data, two modalities that are often presented together in the real world, and explore their meaningful interactions.
To improve upon the cross-modal synergy in existing works, we propose PiMAE, a self-supervised pre-training framework that promotes 3D and 2D interaction through three aspects. Specifically, we first notice the importance of masking strategies between the two sources and utilize a projection module to complementarily align the mask and visible tokens of the two modalities. Then, we utilize a well-crafted two-branch MAE pipeline with a novel shared decoder to promote cross-modality interaction in the mask tokens. Finally, we design a unique cross-modal reconstruction module to enhance representation learning for both modalities. Through extensive experiments performed on large-scale RGB-D scene understanding benchmarks (SUN RGB-D and ScannetV2), we discover it is nontrivial to interactively learn point-image features, where we greatly improve multiple 3D detectors, 2D detectors, and few-shot classifiers by 2.9\%, 6.7\%, and 2.4\%, respectively.
Video
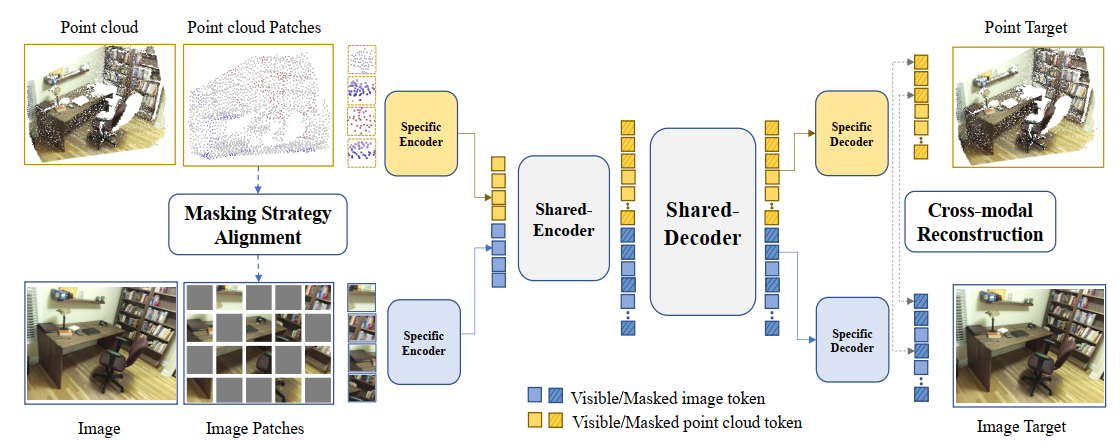
PiMAE Pretraining Pipeline
The point cloud branch samples and clusters point cloud data into tokens and randomly masks the input. Then the tokens pass through the masking alignment module to generate complement masks for image patches. After embedding, tokens go through a separate, then shared, and finally separated autoencoder structure. We lastly engage in a cross-modal reconstruction module to enhance point cloud representation learning.
BibTeX
@inproceedings{chen2023pimae,
title={PiMAE: Point Cloud and Image Interactive Masked Autoencoders for 3D Object Detection},
author = {Chen, Anthony and Zhang, Kevin and Zhang, Renrui and Wang, Zihan and Lu, Yuheng and Guo, Yandong and Zhang, Shanghang},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
year={2023}
}Acknowledgements
Thanks Nerfies for their wonderful website.